The taxi journey continues

After the release of MonetDB/e Python, which brought the power of MonetDB data analytics to the world of Python embedded databases, we set out to expand its reach to the Java environment. Our goal is to provide a lightweight, full-featured embedded database that harnesses MonetDB’s columnar analytics power while keeping the familiar JDBC interface. The power of a full-fledged database server at your fingertips as an embeddable library.
Why NYC Taxi Benchmark?
The NYC Taxi Benchmark is a well known benchmark among the data scientists that leverages on 1.1 billion Taxi and Uber trips made in New York City between 2009 and 2015.
The code for this experiment can be found in the monetdb-examples repository. It relies on a single month of data from the original dataset, i.e. about 1.5GB of raw data and three statistical queries: counting distinct values, statistics over groups, and a regression query. We have tested a ‘’Distinct’’ query that counts over all rows and basically benchmarks the hash table implementation to weed out duplicates. To what concern the ‘’Frequency’’ query, it is a nice and simple form for testing the aggregation performance since this dataset has a decent frequency of events.
The last comparison is a machine learning example with the NYC taxi trip dataset.
How to use it?
MonetDB/e Java uses the core functionalities of our embedded solution to implement the JDBC 4.3 API, resulting in a powerful and easy-to-use library. Using the JDBC interface makes migration from the older, legacy systems easier and allows developers to get hands-on experience with the capabilities of MonetDB/e quickly. While the API is not implemented in its entirety yet, all the main features from the Python and C versions are available. The full documentation can be found here.
To use MonetDB/e Java, you can either add its Maven dependency to your project, or download the JAR file.
<dependency>
<groupId>org.monetdb</groupId>
<artifactId>monetdbe-java</artifactId>
<version>1.10</version>
</dependency>
After installing, you can use it through the DriverManager interface by passing it a valid MonetDB/e Java URL:
jdbc:monetdb:memoryfor in-memory databasesjdbc:monetdb:file:<databaseDirectory>for persistent storage in the filesystemmapi:monetdb:<host>[:<port>]/<database>for connecting to another running MonetDB instance as a proxy. The username and password for the remote connection can be set through either the connection string (as an URL query?user=monetdb&password=monetdb) or the Properties object used inDriverManager.getConnection().
The following example shows how to connect to an in-memory database, execute a query and retrieve the first column of the results:
Connection c = DriverManager.getConnection("jdbc:monetdb:memory:");
Statement s = c.createStatement();
ResultSet rs = s.executeQuery("SELECT * FROM tables;");
while (rs.next()) int tableID = rs.getInt(1);
You can find more examples in the monetdbe-examples repository on Github.
How does it perform?
To experience the performance of MonetDB/e Java quickly, we repeated the NYC Taxi benchmark from our previous blog post and compared it against the most popular database options in the Java world: SQLite, H2, and HSQLDB.
The experiments ran on an Apple Macbook Pro, with 2.7 GHz Quad-Core Intel i7 (6820HQ - Skylake), 16GB 2133 MHz LPDDR3, 512GB PCIe-based flash storage, MacOS BigSur (11.2) and Java SE 15 (JDK 15.0.2)
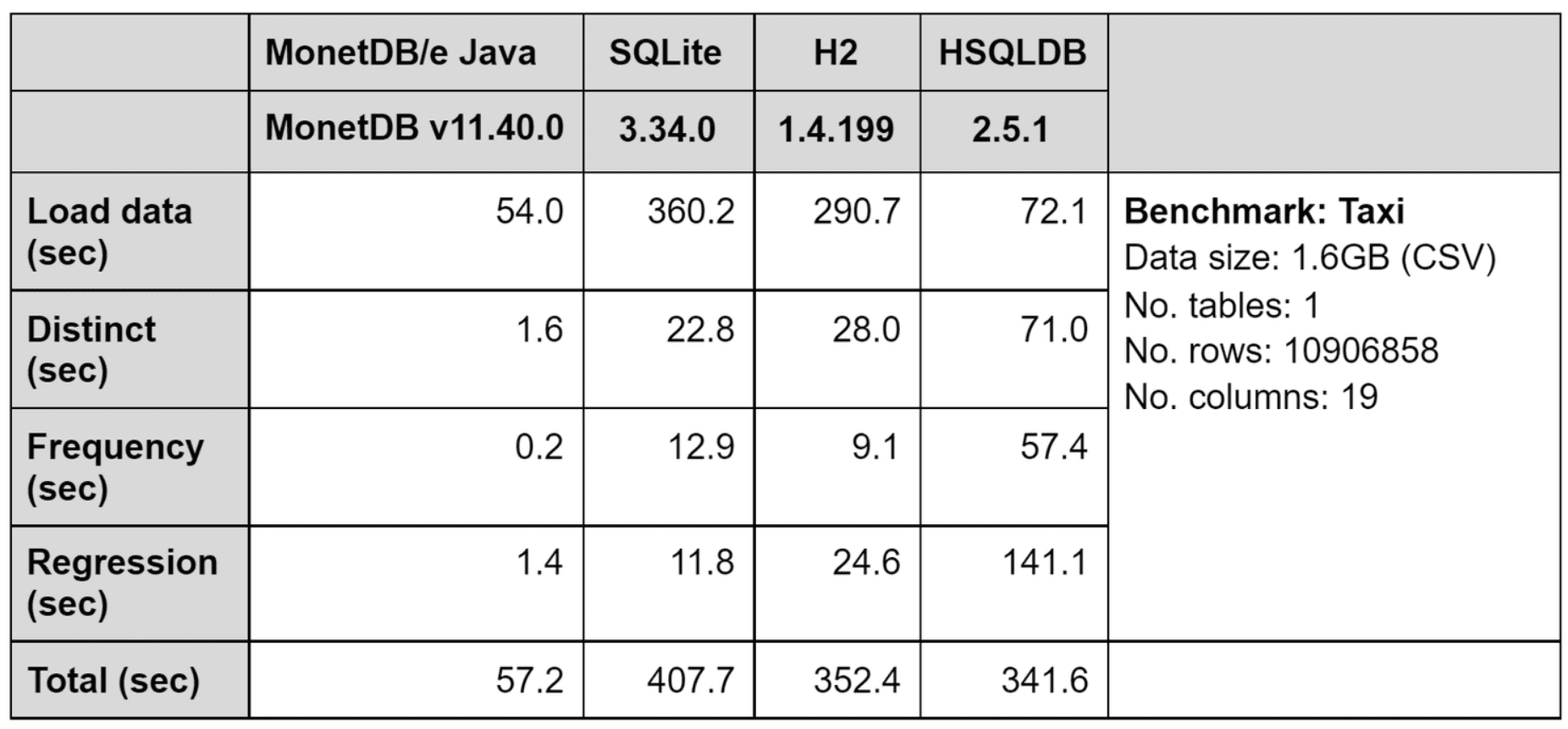
All four database systems used their in-memory, default settings. The table above reports the minimum time of three consecutive executions. For H2, the JVM needed to be configured with a maximum memory of 13GB (-Xmx13312M) to load the dataset. In the HSQLDB experiment, we used a TEXT TABLE to bulk load the CSV data. It is the closest to MonetDB’s COPY INTO statement.
Overall, MonetDB/e Java is 6 - 7 times faster than the reference systems for the complete run, while for individual queries, MonetDB/e can be almost 300 times faster.
MonetDB/e Java seems to be faster than its competitors in both the Distinct, Frequency and Regression queries, confirming the higher performances in hash table implementation, aggregation performances and regression formulation.
However, this is only the result of one benchmark. We encourage users from the Java community to challenge MonetDB/e with more use cases to identify its strong and weak points.
Where does MonetDB/e make a difference ?
No one-size-fits-all database management system exists, and MonetDB/e is not a silver bullet either. However, replacing H2, SQLite, or HSQLDB with MonetDB/e should be considered in the following cases:
- You want to process larger amounts of data.
- You want to exploit the multi-core hardware architecture that has become the norm to do the job efficiently.
- You want the breadth of functionality offered by a full-fledged SQL DBMS.
- You want analytical functions, fast grouping, and fast data loading.
- You want a seamless path from prototype development using the in-memory mode to server-based production deployment.
Not immediately convinced? Just try it out on a sample application or get inspired by the showcases in the monetdbe-examples repository.
What are the caveats?
There are a few caveats for Java programmers. Most database systems and MonetDB/e Java do not align 100% on the same interpretation of the SQL standard. MonetDB/e is much more strict. This misalignment may result in minor differences in error handling or even some surprises in the results returned when it concerns null handling, rounding statistics and aggregate queries. However, addressing those issues in your application will only improve its quality because it becomes more portable. If you have problems or questions, please let us know through Github or Stackoverflow.
What can you expect?
The MonetDB/e Java library uses the July 2021 candidate release of MonetDB. Several rough edges and missing features will be dealt with before the library becomes an official feature release later this summer. Still, users are encouraged to try this pre-release. Please drop us a line about your experiences or share this post - your feedback is essential for the continued improvement of the MonetDB ecosystem.