Group commit
A.k.a. how to get 4x higher throughput for concurrent, non-conflicting INSERTS
In the VesselAI project, MonetDB is challenged by many small data insertions at high frequencies from the large number of IoT sensors in the maritime applications. For such real-time data processing applications, high-throughput and low-latency are among the most important requirements. In this blog, we share our journey how we have found the bottleneck and improved MonetDB’s throughput for concurrent INSERTs by a factor of 4.
A central component in the transaction manager of a database system is the Write-Ahead-Log (WAL). It is used to collect a summary of all the changes made to enable transaction rollback and recovery after an error has occurred. Each transaction collects the WAL records in a temporary buffer and continuously flushes them to a WAL log file. Since the WAL records are sequentially written to a single file, concurrently running transactions compete for resources, such as the disk I/O.
The question became “what happens if we want all cores to do simple INSERT queries concurrently?” Although the following is an extreme case and contrived setup, it would show us how on a multi-core system we can use all the resources properly. Up to MonetDB’s Jan2022 release, this led to a scale-up of about four concurrent users stressing the system with a continuous stream of simple INSERT queries.
As a starter, we suspect that the sequential commit to the WAL files is the bottleneck of the write performance. To test this hypothesis, we executed a simple benchmark that compared the insert performance with the WAL on-disk (NVMe) versus in-ramdisk (Google Cloud instance, 32 cores & 32 GB RAM; MonetDB branch Jan2022 was used). Additionally, we used different numbers of inserts per transaction (1 with autocommit=on, 5 and 10 with autocommit=off):
 |
|---|
| Figure 1: MonetDB INSERT throughput |
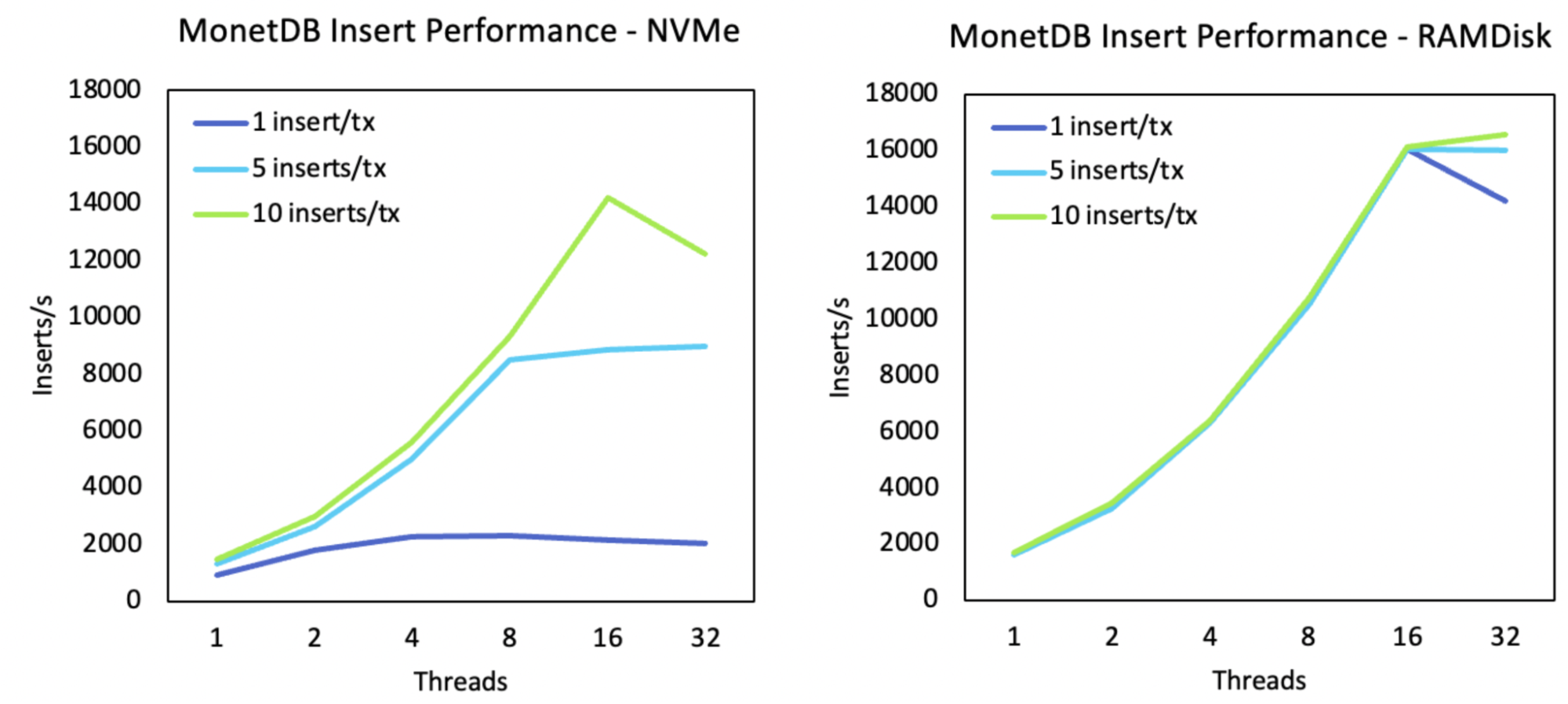
Figure 1 shows before improvement with WAL on-disk versus in-ramdisk. The X-axis shows the number of concurrent transactions (each executed by one thread). The Y-axis shows the throughput of the number of INSERTs per second. The legend shows the number of INSERTs included in a transaction.
Even with an NVMe, the throughput of single insert transactions stagnates after 4 concurrent threads, while with a ramdisk the throughput of transactions of different sizes barely differs. So, conclusion (1): this is a problem with the storage. Furthermore, with the NVMe, the throughput increases when a transaction inserts more data. So, conclusion (2): this is a problem with the commit.
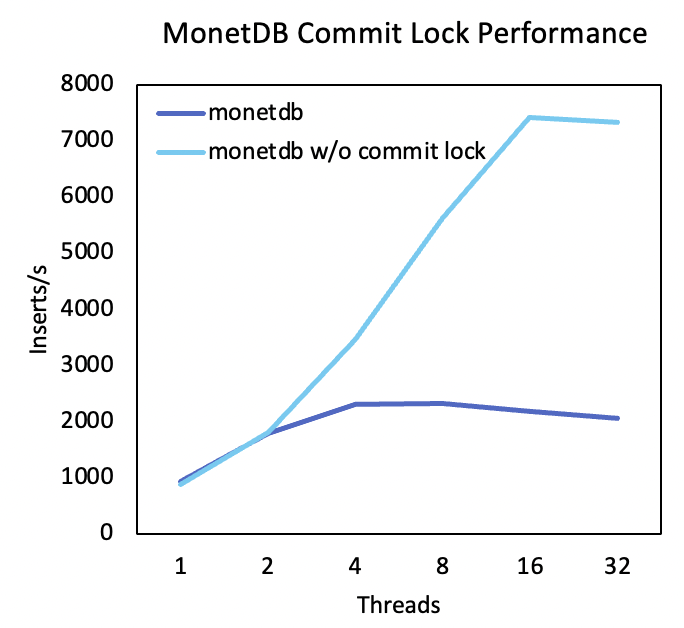
To see if we can remove the bottleneck, we commented out the commit lock in the commit function sql_trans_commit, as shown in this file, and obtained the following results:
 |
|---|
| Figure 2: single INSERT throughput “with” vs “without” commit lock |
Hence, without the commit lock, the throughput of single insert transactions now scales up to 16 concurrent threads on-disk. In addition, when selecting data from the table, into which the data was inserted, the query displayed all data inserted, while the recently committed data was still in the WAL records.
The above experiments have confirmed our hypothesis that the WAL file I/O is the performance bottleneck for concurrent INSERTs. However, simply disabling the commit lock is not a real solution because, in this way, the shared data structures would lose their protections against concurrent read/write to their values. In our experiments with a disabled commit lock, we have noticed that when flushing the WAL logs to the disk, sometimes most of the data disappear and the database crashes with “!FATAL: write-ahead logging failure”.
And before the crash, a new log file would appear while the other one was still there.
To improve MonetDB’s throughput performance for many concurrent small INSERTs without compromising the integrity of the database, we have added a “group commit” feature (7302f87) to MonetDB’s transaction management system. This feature is based on the observation that those INSERTs are non-conflicting and, therefore, the READ UNCOMMITTED isolation would suffice.
With group commit, we no longer conduct the final and expensive step of a transaction commit (in which the WAL logs are flushed to the on-disk file) for each individual transaction. Instead, the flushes of multiple (small) transactions that have been committed shortly after each other are grouped into a single flush action. Group commit can largely reduce the waiting time for many concurrent small INSERTs because the round trip to the disk takes a large part of the total execution time for such small transactions.
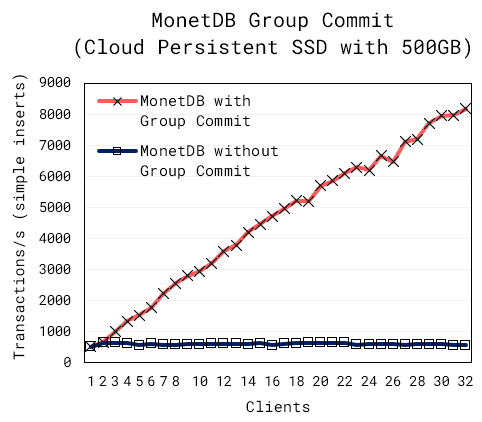
Figure 3 shows that the new group commit feature largely improves the performance of concurrent non-conflicting inserts and the throughput scales linearly with the number of concurrent clients.
Group commit will be included in the next feature release of MonetDB, to be expected later in 2022.
 |
|---|
| Figure 3: INSERT throughput before and after “group commit” optimisation |
We’d like to thank Nuno Faria of INESC TEC for his insert benchmark, the graphs, and his original contributions to the design and implementation of the new group commit algorithm and the UNLOGGED TABLE feature