Citus Data cstore_fdw (PostgreSQL Column Store) vs. MonetDB TPC-H Shootout
The database world recently welcomed a potential new member, Citus Data’s cstore_fdw. cstore_ftw is an extension for PostgreSQL, an Open-Source relational data management system. cstore_ftw uses a decomposed(“column-based”) storage model and features data compression and a zone map index. We are happy to hear that the columnar storage model for relational databases is gaining even more traction in the Open-Source world. At the same time, our experience shows that there is more to a columnar database system than the on-disk storage layout. In particular, the bulk processing model (and other advances discussed in one of our papers) is crucial to getting maximum data management performance from modern hardware. Since cstore_ftw is using PostgreSQL’s volcano-style query processor, we immediately suspected that this component would be the limiting factor to its performance.
We therefore ran a small experiment, where we loaded synthetically generated data from the TPC-H benchmark into three relational database systems: (Vanilla) PostgreSQL 9.3.4, cstore_ftw (GIT snapshot from 2014-04-06). our Open-Source columnar database system. All experiments were run on desktop-class PCs that contained an Intel i7-2600K CPU at 3.40GHz and 16GB of main memory. The operating system used was Fedora 20 with kernel version 3.12.10.
We tested a data set with a total size of 5.2 GB agenerated as CSV files with TPC-H scale factor 5. The dataset was loaded into the three database systems tested. Then, we ran the 22 TPC-H SQL queries on the systems and measured the (wall clock) time it took to produce a result. Since caching effects play a major role in this, we controlled for that by performing cold and hot runs. In cold runs, the database is stopped, all file system caches are emptied. Then the database is started up, a single query is run, the database is stopped again, and the whole process repeats. For hot runs, we start up the database, and run all queries twice to warm up various caches. For both cold and hot runs, every query was ran five times to control for random fluctuations in IO performance and system background activity. The following graphs illustrate the results:
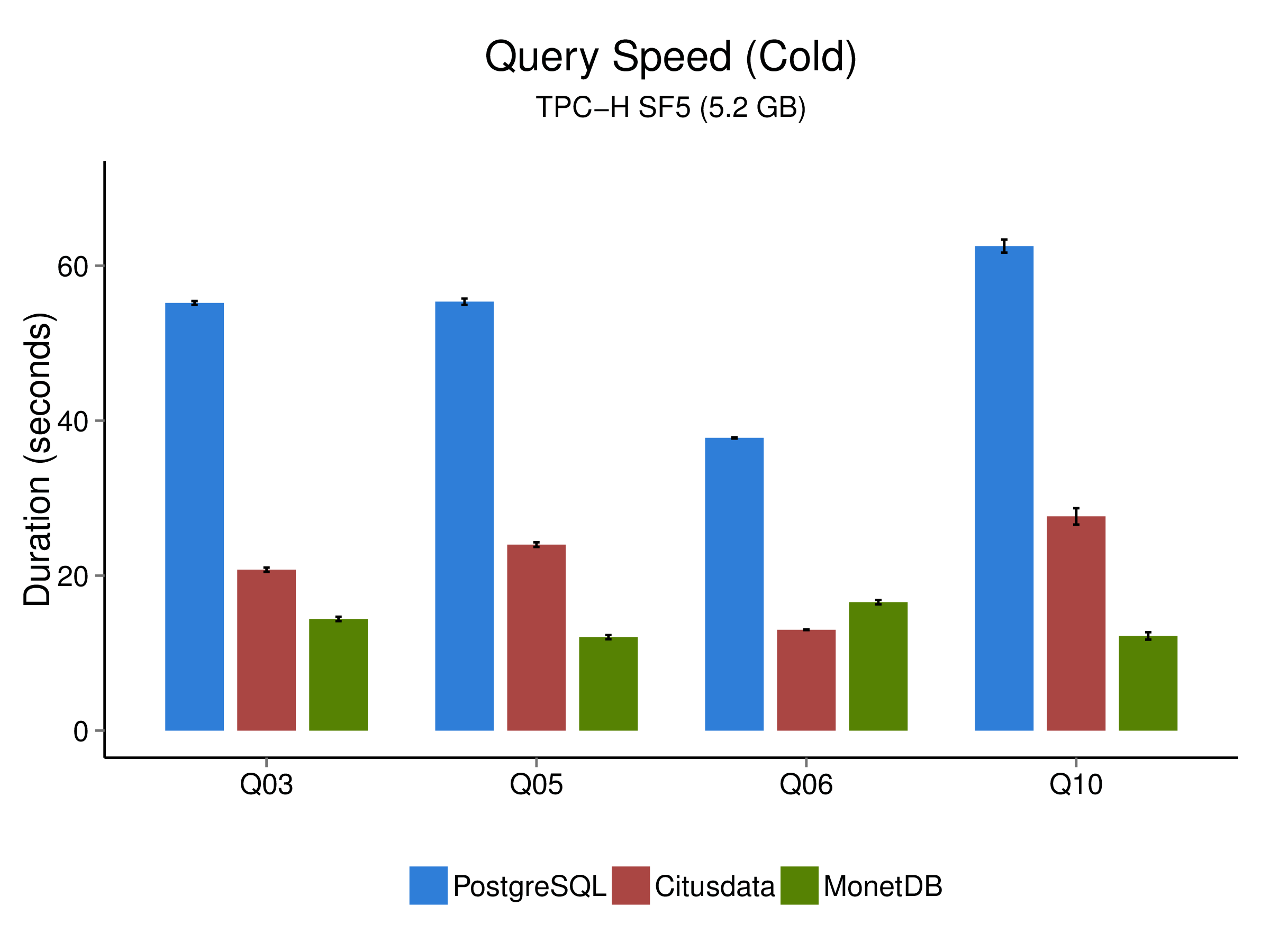
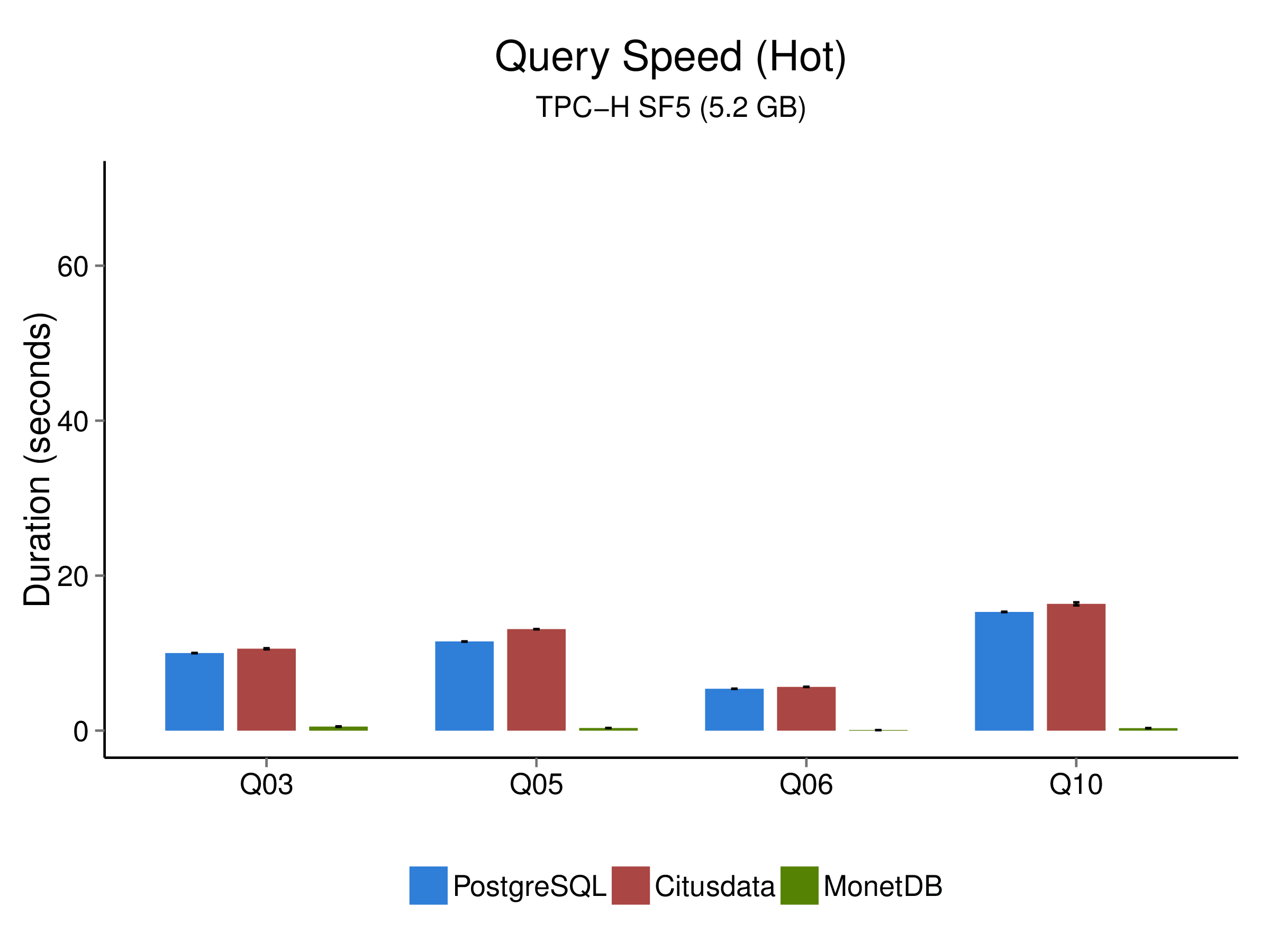
As you can see, while cstore_ftw is able to outperform its “host” PostgreSQL in the cold runs, where no data is cached at all, the same is not true for the hot runs. The reason for this should be clear from the above, since cstore_ftw lacks a column-based query processor, it can only gain speed from being faster in loading data from disk. While this is arguably often the case in analytical workloads, the margin by which MonetDB outperforms cstore_ftw shows that only switching storage models alone is probably not enough. We will follow cstore_ftw’s development and update this post if applicable. The scripts we used to generate the plots above are available on GitHub.
About the Author
Dr. Hannes Mühleisen is a researcher at the Database Architectures group at CWI, and member of the MonetDB development team. Contact Hannes at hannes@cwi.nl or on Twitter.
Update/Clarification
Apparently, there was some confusion between the different products offered by Citus Data, the company. CitusDB is their shared PostgreSQL offering, which has nothing to do with cstore_ftw, their experimental columnar PostgreSQL extension. As in their original post, we compared the latter to vanilla MonetDB and PostgreSQL.